The SOC is Fully Covered (And Still Completely Surprised): The detection gap your stack can't see.

The number of detection tools in the average SOC has tripled in the last five years. The number of alerts they generate has tripled too. The number of breaches discovered weeks or months after the fact hasn't moved.
That's a context problem, and stacking more rules on top of more tools doesn't fix it.
This is the playbook for security leaders who are tired of the post-mortem that always reads the same way: "the signals were there, we just couldn't see the sequence."
The short version of what changes:
- Stop ranking by alert severity. Detection rules tell you what could matter in theory. They don't know what's exploitable in your environment, what's already mitigated by your controls, or what's part of a multi-step intrusion that no single rule will ever catch.
- Start ranking by attack-path reachability. Whether a signal can actually reach a crown-jewel asset, given your current identity model, network position, and active control coverage, matters more than the severity score the SIEM assigned.
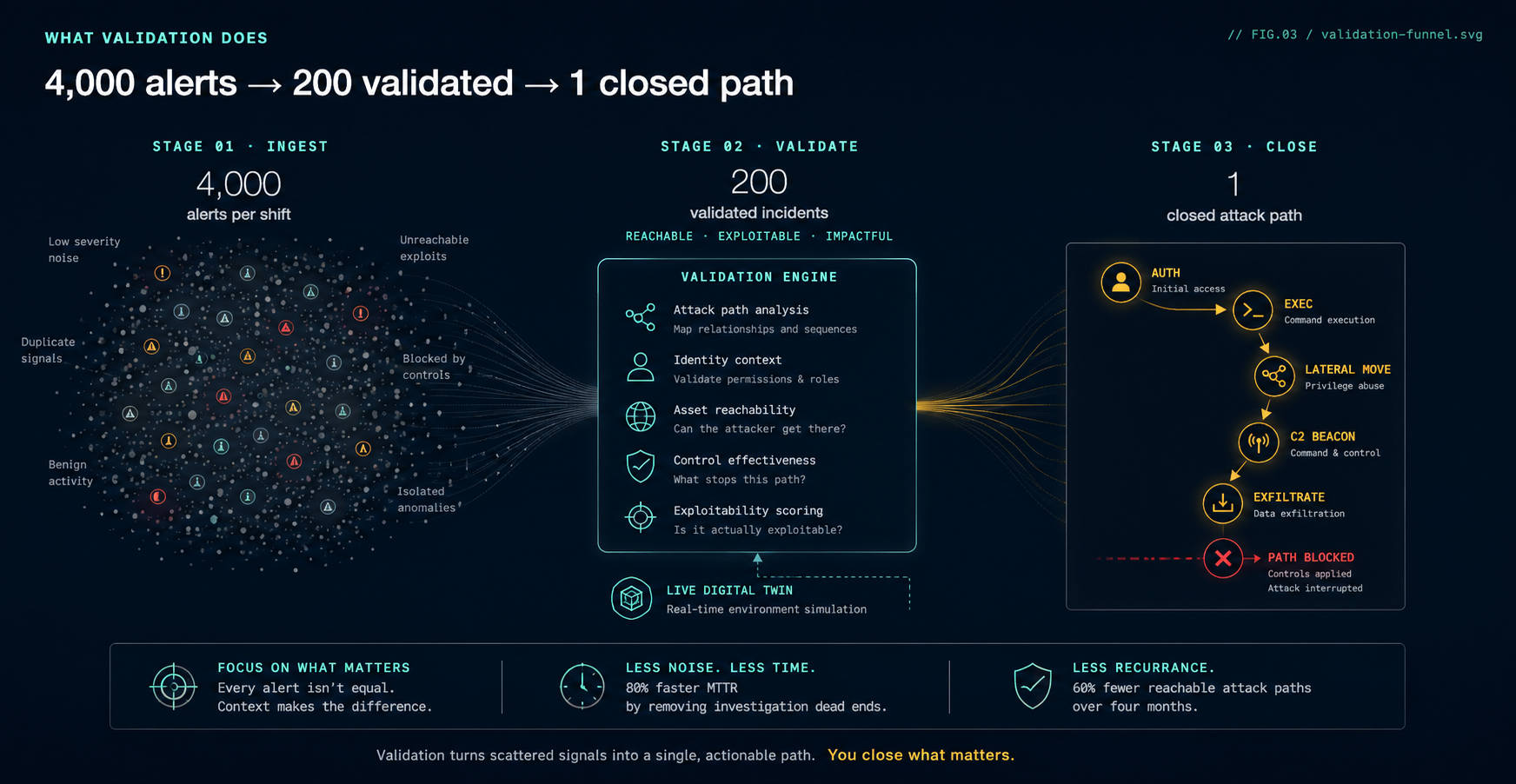
- Validation cuts more time than automation does, faster. One Tuskira customer reduced their alert volume by 95%, accelerated mean-time-to-respond by 80%, and cut active attack paths by 60% by validating every alert against a live digital twin before triage, not by hiring more analysts.
- The choice between "more detection" and "better response" is a false dichotomy. You need both, but the order matters, and the order is determined by validated context, not signature matching.
If your SOC is running 24/7 and the dwell time still climbs, the next 2,500 words are for you.
Why your stack keeps drowning (and more tools won't save you)
In the average enterprise, the security tool stack now includes 50 to 80 distinct products. Each one generates its own stream of detections, findings, and recommendations. A typical Tier-1 analyst now sees thousands of alerts per shift but can meaningfully investigate maybe twenty. The other 99% become noise the team has trained itself to ignore.
That training is the problem, because real intrusions don't show up as a single screaming alert. They show up as a sequence. A normal-looking login. A suspicious-but-allowed PowerShell. A scheduled task that blends in. A beacon hidden in HTTPS. An identity reused in a place it shouldn't be. Lateral movement disguised as business as usual. Individually, none of these steps reads as an incident. Together, they're the entire story.
The SolarWinds compromise is the canonical example. Scanners flagged anomalies. Detection rules fired. The signals existed. What didn't exist was a system that correlated those signals across the exposure layer, the SOC, and the control plane into a single chain. Defenders technically knew about the issues. They just couldn't see the path.

If you're reading this and thinking, "we'd catch that today," then look at your dashboard. How many "low" or "medium" findings are open right now on internet-exposed assets running as service accounts? How many "informational" auth events involved an identity with admin privileges? Your stack flagged all of these. Did your SOC investigate any of them?
If your tools can't tell you, then you may be operating the way SolarWinds was operating the week before disclosure.
Related reading: If the Attack Path Still Exists, You Haven't Solved the Incident
Why "alert per rule" is the wrong lens
Most detection stacks still treat the alert as the unit of work. A rule fires, an alert lands in the queue, an analyst triages. Repeat ten thousand times per day.
That model was built for a world where attacks looked like single events, but unfortunately, they don't anymore.
Here's what an alert-by-rule lens doesn't know about your environment:
- Behavioral baseline. Is this PowerShell invocation normal for this user, this system, this time of day, in this context? An IOC-based rule doesn't ask. It just checks for a string match.
- Identity reachability. Is the affected service running as a low-privilege account that touches one VM, or as a domain admin with cross-tenant access? The rule doesn't know.
- Control coverage. Is there a WAF rule, EDR signature, or IAM policy already blocking the exploit path this alert hints at? The rule doesn't check.
- Chainability. Can this single "medium" alert combine with two unmonitored misconfigurations and an over-privileged role to produce a viable attack path to your customer database? The rule isn't built to answer that.
- Business criticality. Is the affected asset a tier-one revenue system or a forgotten test instance? The rule treats them the same.
So you end up with a queue where a CVSS 9.8 alert on an air-gapped lab box sits ahead of a sequence of "low-severity" anomalies on an exposed customer API that, taken together, describe a real intrusion. The first one your analyst will close in five minutes. The second one will become the breach report.
This isn't a bug in the detection rule. It's a misuse of it. Rules classify events. They don't reason about paths. Treating them as your queue is how SOCs end up "fully covered" by every framework and still surprised on Monday morning.
Related reading: The Future SOC Understands Behavior, Not Just Alerts
Attackers exploit your noise, not your tools
Once you start thinking like a modern attacker, the SOC reorganizes itself. Attackers aren't trying to bypass your EDR. They're trying to look unremarkable inside it, and that's a different game that AI has made it dramatically easier to play. We're seeing three patterns repeat across investigations:
- Noise flooding. Threat actors use LLMs to generate dozens of unique phishing payloads per persona in your org, each tuned to trigger detection rules in ways that mimic false positives. Mismatched domains. Typosquats of whitelisted services. Idle RDP sessions. Sleep timers. DNS tunneling decoys. The goal isn't to slip past your SOC. The goal is to exhaust it. Your Tier-1s now spend their day chasing carefully crafted fakes while the real intrusion happens in the gap.
- Adversarial alert engineering. Attackers are treating your detection stack as a puzzle to reverse-engineer. They observe tuning behavior on shared platforms, feed leaked SIEM rule logic into fine-tuned models, and run their payloads against open-source detection rule sets (Sigma, YARA) before deployment. Once they know what your stack will flag, they shape their behavior to fit in the gaps your rules can't fill.
- AI-driven internal recon. After initial access, attackers feed IAM policy documents, GPO settings, vulnerability scan output, and user activity logs into an LLM and ask it for the quietest path to the crown jewels. The same exercise a red team would run in hours now happens in minutes, and it prioritizes pivots designed not to trip detection.
Notice what's common across all three: the attacker isn't beating your tools. They're using your noise. If your detection volume is your defense, that defense scales linearly. The attacker's evasion capability now scales exponentially. The gap widens every quarter.
Related reading: Are Attackers Already Using AI Against Your SOC?
The operational assumptions quietly breaking modern SOCs
Most SOC modernization efforts optimize throughput rather than attackability. More tools create more detections. Faster triage improves queue velocity. Automated playbooks accelerate response workflows. But none of these change whether the underlying attack path is still reachable.
A SOC can process ten thousand alerts per week and still be structurally blind to the sequence that matters. Speed compounds value when the work is correct. It compounds noise when it isn't.
That's the optimization trap modern SOCs keep falling into: mistaking operational activity for reduced exposure.
The problem is that most workflows still treat alerts as isolated events rather than as evidence within a larger attack chain. More telemetry, more enrichment, and more automation improve throughput, but they don't inherently improve visibility into how attackers actually move.
The result is a SOC that gets faster every quarter while remaining vulnerable to the same classes of intrusion.
Closing the case doesn't close the path
Containment fixes the instance. It doesn't fix the structural route the attacker used.
The same lateral movement corridor, identity relationship, or control gap is often still available elsewhere in the environment, waiting for the next intrusion that appears slightly different on the surface.
This is why so many organizations experience recurring attack patterns despite continuously improving operational metrics. The case was resolved. The path was never eliminated.
ATT&CK coverage isn't adversary coverage
Coverage maps are useful reference models, but they don't prove adversary interruption in your environment.
A mapped technique only matters if the deployed controls, telemetry, and surrounding context actually detect the sequence under real operating conditions. A SOC can appear fully covered on paper while remaining blind to the relationships that turn isolated signals into a reachable breach path.
That's the distinction most dashboards still fail to capture.
Related reading: From Playbooks to Intelligence in Your SOC
Automate or validate? Both, but stop pretending they're the same thing
The most common version of the SOC modernization debate frames it as a binary: should we automate our existing workflows (faster), or do something fundamentally different (smarter)?
It's the wrong framing. The answer is both. But, and this is the part that gets skipped, the order matters, and the order is determined by whether the threat is real.
Here's how to think about it:
- Automation is a force multiplier on validated work. A playbook for enrichment, escalation, or ticket creation is a legitimate force multiplier when the alert it's reacting to has already been confirmed exploitable in your environment. Speed compounds value when the input is correct.
- Validation is a noise filter on raw work. AI Analysts running on a live digital twin simulate attacker movement across your specific identity, network, and control graph, then determine whether the alert in front of them describes a viable attack path or a theoretical one. Speed before validation just produces fast wrong answers.
The smart sequence isn't "automate, then validate." It's "validate first, then automate the result." Sometimes that means an AI Analyst suppresses nineteen out of twenty alerts because none of them can reach anything that matters. Sometimes that means one alert gets escalated with a complete attack chain, recommended control changes, and validated reachability already attached.
The SOCs still arguing "automate vs. AI" are the ones losing the most time. The SOCs winning have stopped treating it as a debate and started treating it as a sequence.
A real case: 95% noise reduction, 80% faster response, 60% fewer paths
This is the number we want every security leader to internalize.
A SOC team operating a complex stack (Splunk, Microsoft Defender, CrowdStrike, AWS GuardDuty, dozens of integrations) was averaging more than four thousand alerts per shift. Mean time to respond had crept past thirty-eight minutes. Dwell time on confirmed compromises was running in the days. Two paths were available:
Path A: Hire more analysts. Add more tuning capacity. Buy another SOAR. Accept that throughput will improve but the math won't.
Path B: Validate every alert against a live digital twin of the environment before it ever lands in the analyst queue.
They picked Path B. Here's what happened:
- 95% noise reduction. Validation removed alerts where the targeted asset wasn't reachable from the attacker's apparent position, where existing controls already neutralized the exploit, or where the activity was structurally identical to a known-good behavior pattern in that user's history. The remaining 5% were real candidates for human review.
- 80% faster mean time to respond. With the analyst queue cut down to validated incidents only, MTTR dropped from thirty-eight minutes to under eight. The time savings didn't come from faster triage. They came from skipping triage on alerts that should never have reached the analyst.
- 60% reduction in active attack paths. With validated incidents came validated remediations. Each confirmed compromise was mapped to its underlying attack chain, and control changes (IAM tightening, segmentation refinement, detection logic updates) were applied at the path level, not the instance level. Over four months, the number of reachable paths from external entry points to crown-jewel assets dropped by 60%.
The number to remember isn't any one of those percentages. It's what they describe together: a SOC that stopped processing alerts and started reducing attack surface.
Related reading: Why Orchestration Beats More Tools (and More Noise)
What a learning SOC actually looks like
If you're rebuilding your SOC for 2026, the playbook is:
1. Lead with sequence, not signature. Every detection gets enriched with the surrounding behavior, identity context, asset criticality, and prior signal history before it becomes work. A single rule firing isn't an alert. A sequence of correlated activity is.
2. Validate exploitability through simulation, not assumption. A digital twin (a live, virtual replica of your production environment built from your existing telemetry) lets you confirm whether an exploit path is actually reachable in your environment before assigning a response ticket. This is the difference between "this rule fired somewhere" and "an attacker can walk from this signal to your production database in three hops."
3. Treat closing the path as the win condition, not closing the case. A case is closed when the immediate instance is contained. A path is closed when the structural route, equivalent identity relationships, comparable control gaps, parallel misconfigurations, are eliminated globally. Containment is necessary. It just isn't sufficient.
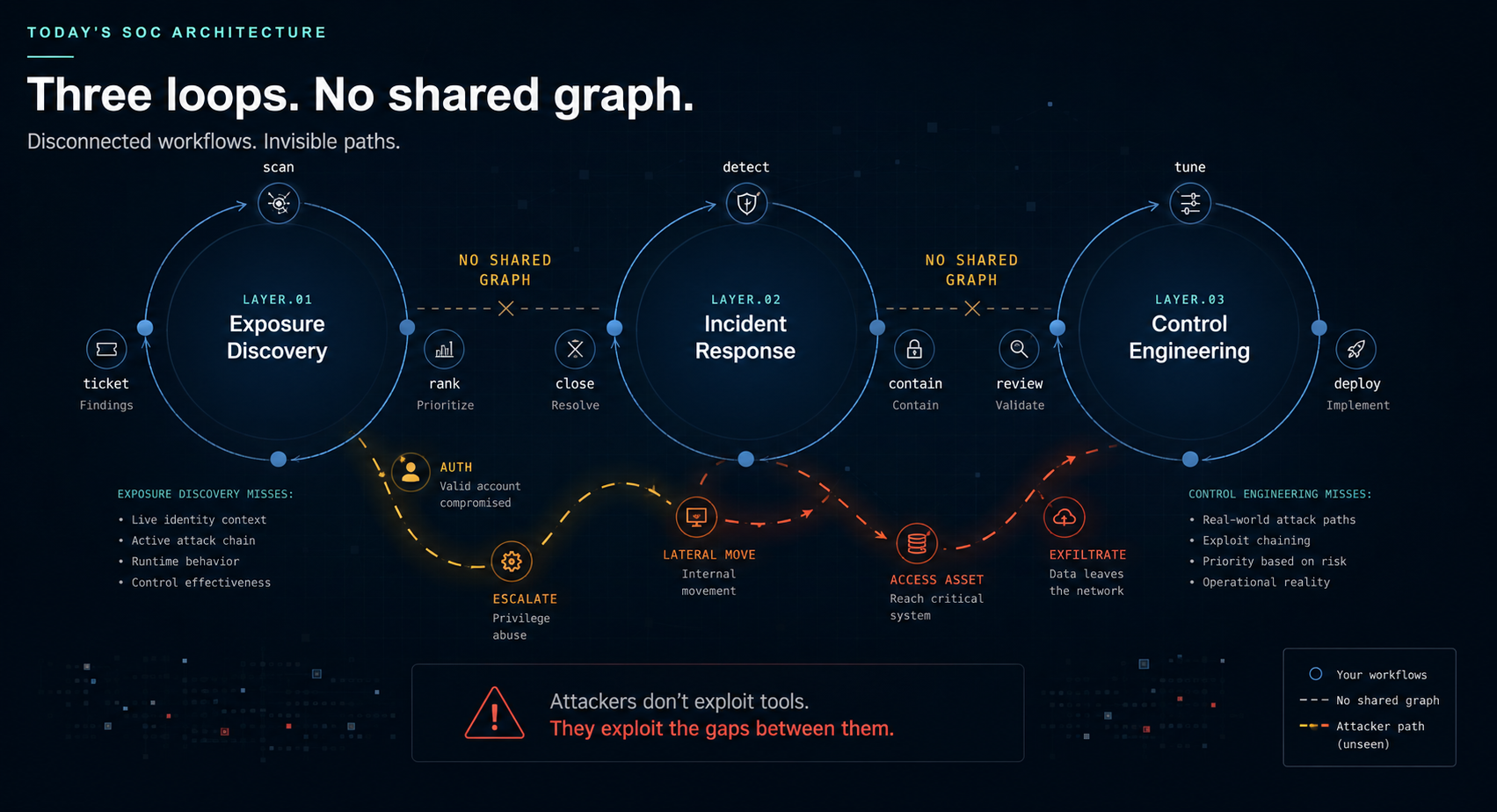
4. Unify the three loops on a shared graph. Exposure discovery, incident response, and control engineering operate as separate workflows in most enterprises. They generate findings, file tickets, and update policies in parallel. A learning SOC runs them on a single graph of assets, identities, controls, and reachable paths, so the output of one becomes input to the others automatically.
5. Measure attack-surface reduction, not case throughput. "Alerts resolved per analyst" is a vanity metric. "Reachable attack paths to crown-jewel assets, month over month" is the real one. The first rewards processing noise. The second rewards eliminating exposure.
The SOCs getting this right are seeing the kind of numbers in the case above, not by detecting better, but by stopping the detection of things that were never exploitable to begin with.
Related reading: The Vulnerability Backlog Problem: Why Patching Faster Isn't the Answer
The metric that matters
Security operations programs measure many things: alert volume, mean time to respond, case closure rates, analyst productivity. These metrics describe activity. They don't describe improvement.
A learning SOC has to be evaluated on whether it reduces recurrence and reachability over time, and that requires tracking metrics tied to attack mechanics.
- Repeat incident class frequency should decline. If ransomware, identity abuse, or privilege escalation patterns reappear at the same rate quarter over quarter, the underlying conditions enabling them remain intact.
- Reachable breach path count should trend downward. This reflects the number of viable attack chains from initial access to sensitive assets under current identity, network, and control conditions. If that number is static, your risk posture is static, regardless of what your MTTR dashboard says.
- Control interruption coverage should increase. Controls should demonstrably interrupt realistic attack chains across identity and network boundaries, not just exist as policies in a binder.
These metrics move the conversation from operational efficiency to structural risk reduction. They answer the only question that matters: whether the environment is becoming less attackable over time.
If the answer is no, your SOC is processing incidents. It isn't preventing them.
Where this leaves you
The Equifax-style breach narrative used to be about a missed patch. The modern version is about a missed sequence: a signal that fired in one place, a context that mattered somewhere else, and a control gap that was technically known but never structurally closed. Your tools saw all of it. Your SOC saw none of it.
The shift isn't to a new tool. It's to a different unit of work. The SOC that wins in 2026 doesn't process more alerts faster. It processes fewer alerts, each one validated, and uses every confirmed compromise to systematically reduce what's reachable next time.
Less time. Less noise. Less recurrence. That's the only outcome that compounds.
Frequently asked questions
Why do SOCs still miss real attacks despite full ATT&CK coverage?
Coverage maps are referential. They tell you what attack techniques your stack can theoretically detect, but they don't tell you whether those rules, if deployed against the assets you have running today, would actually catch the technique in your environment. Real attacks unfold as sequences across multiple tools, identities, and time windows. A coverage map captures individual technique detection. It doesn't capture the gap between detection and validated attack-path reachability, which is where modern intrusions live.
What's the difference between alert validation and threat validation?
Alert validation asks, "Is this alert a true positive?" by comparing signal quality to the rule that fired. Threat validation asks "is this exploitable in my environment, right now, given my actual identity model, network posture, and control coverage?" The first one trusts the rule. The second one tests the path. A SOC running on alert validation will keep closing well-tuned alerts on assets attackers can't reach, while real attack paths sit open elsewhere.
What is a Digital Twin for SOC operations?
A Digital Twin is a live, virtual replica of your production environment (assets, identities, network paths, control coverage, exposure state) built and continuously updated from your existing security telemetry. It lets the SOC safely simulate exploit scenarios against the replica to confirm whether a given alert describes a reachable, exploitable attack path in your specific environment before committing analyst time. Tuskira's Digital Twin is the foundation of how Kairo (our breach-path detection and disruption capability) decides which signals describe real risk and which describe theoretical risk.
How do you measure SOC effectiveness without using MTTR?
MTTR measures how fast you close work. Effectiveness measures whether the work was the right work. Better leading indicators: reachable breach path count to crown-jewel assets (should trend down month over month), repeat incident class frequency (should decline as structural paths are closed), and control interruption coverage against realistic attack chains (should increase as defensive posture improves). These metrics describe whether your environment is becoming less attackable, which is the only thing the SOC is actually paid to improve.
Gartner Profiles Tuskira as a Tech Innovator in AI Agent Reasoning

Gartner's Latest Research on Agentic AI Reasoning: What It Means for Enterprise Security
