The Amnesia Problem in AI SOCs: What Learning Actually Means

When Maya’s team rolled out their new AI SOC tool, it felt like a turning point. Alerts were summarized cleanly, and investigations read like well-written case notes. The system confidently explained why it escalated one incident and ignored another.
Leadership was told the system would learn over time. Correct it when it was wrong. Confirm it when it was right. The AI would adapt to the environment like a junior analyst who never slept. However, three months in, Maya realized that though AI was faster, it wasn’t getting smarter.
It remembered past conversations, verdicts, and corrections, but when a familiar attack pattern resurfaced, the investigation still had to be re-explained. The system could recall that an alert had once been marked benign or malicious, yet it couldn’t explain how the attack actually unfolded, why certain evidence mattered, or which assumptions had failed last time.
It remembered outcomes, not understanding.
Most AI SOC tools’ learning is built on chat memory. Feedback is stored as conversational context, not as structured knowledge. When an analyst corrects the system, the AI remembers the correction but not the attack path, the investigative logic, or the defensive gap that made the incident possible. The result looks like progress, but behaves like amnesia.
Most AI SOC tools can remember what happened, but very few can explain how an attack actually worked.
What Most AI SOCs Mean by “Learning”
When vendors say an AI SOC “learns,” they’re usually describing a conversational feedback loop. The system summarizes alerts, proposes conclusions, and waits for corrections or confirmations. If an analyst nudges the system toward the right answer, that exchange is stored and reused as context later.
That’s chat memory. It shortens back-and-forth and improves conversational fluency
When Maya corrects the AI, the system records whether the conclusion was right or wrong, but it doesn’t decompose the attack into steps, extract the sequence of actions the attacker took, the assumptions the investigation relied on, or the control failure that made the incident possible. That reasoning stays in the analyst’s head.
Remembering what was said is not the same as learning how an attack works, and in security operations, where the same techniques reappear under slightly different conditions, that distinction is the difference between responding faster and actually getting better.
Why Chat Memory Fails in Real SOCs
In a SOC, investigations are messy, repetitive, and distributed across shifts, analysts, and tools. Chat memory breaks down because it is episodic, as each investigation lives as a thread of text, bound to a moment in time, and full of assumptions that are never made explicit.
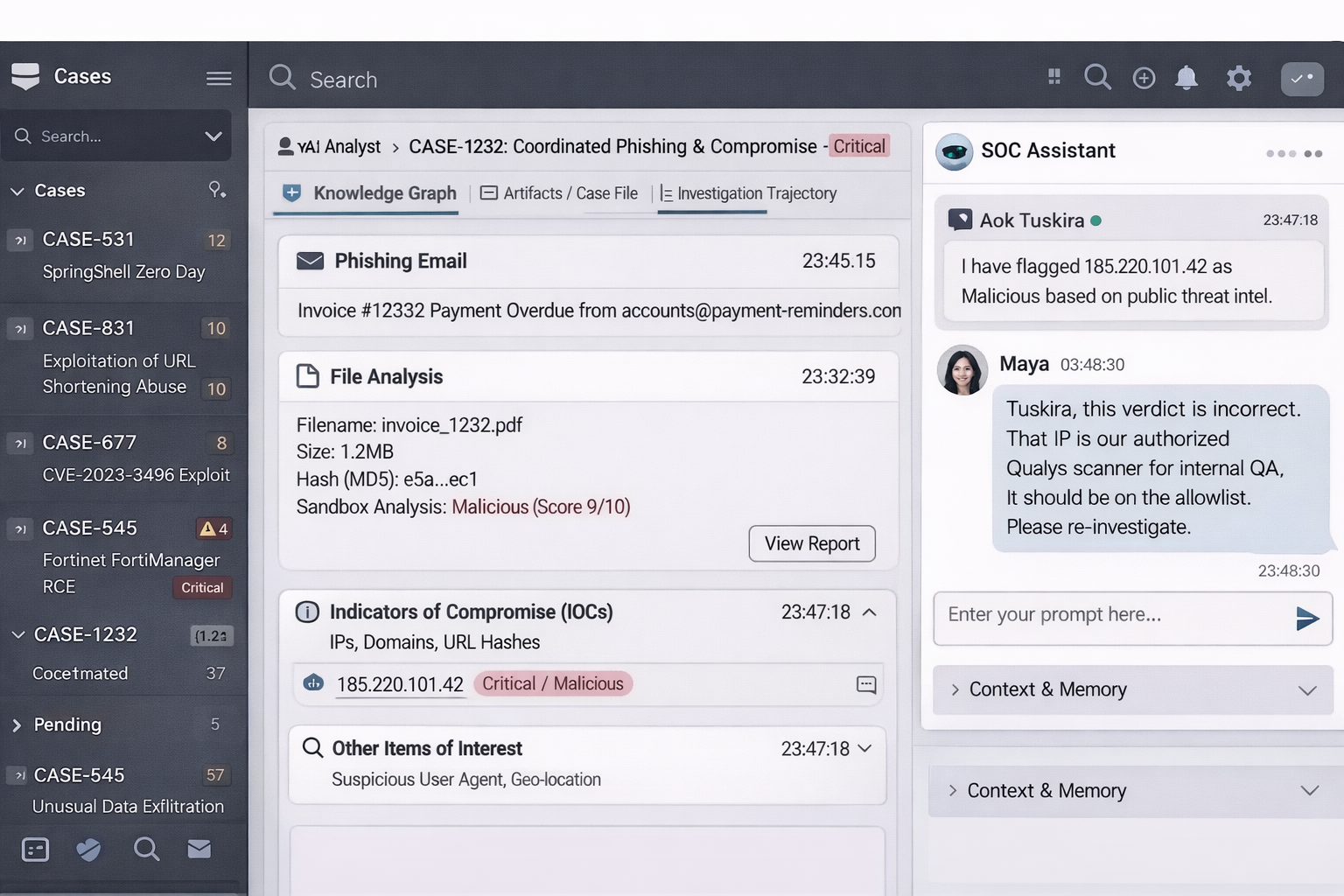
Maya saw this most clearly with phishing. One afternoon, she corrected the AI, pointing out that the real signal wasn’t the email itself but the delayed OAuth consent that followed hours later. The AI accepted the correction, but the next day, a nearly identical campaign surfaced. Different sender with the same infrastructure pattern, and identity abuse.
The AI still needed to be walked through the logic again. The prior “learning” hadn’t carried over. It was trapped in yesterday’s conversation.
Nothing in chat memory changes the environment. A corrected phishing investigation doesn’t harden identity controls. A clarified ransomware analysis doesn’t close the lateral movement path that enabled it. The AI may sound more confident explaining what happened last time, but the same conditions remain in place, waiting to be exploited again.
And if you work in SOC, do you just need faster answers? Or do you need systems that convert investigation effort into lasting change?
The Shift: From Chat Memory to Structured Learning
The way out of this trap is to stop treating investigations as conversations to be remembered and start treating them as work products to be preserved. A learning package is the difference between closing a case and changing the system.
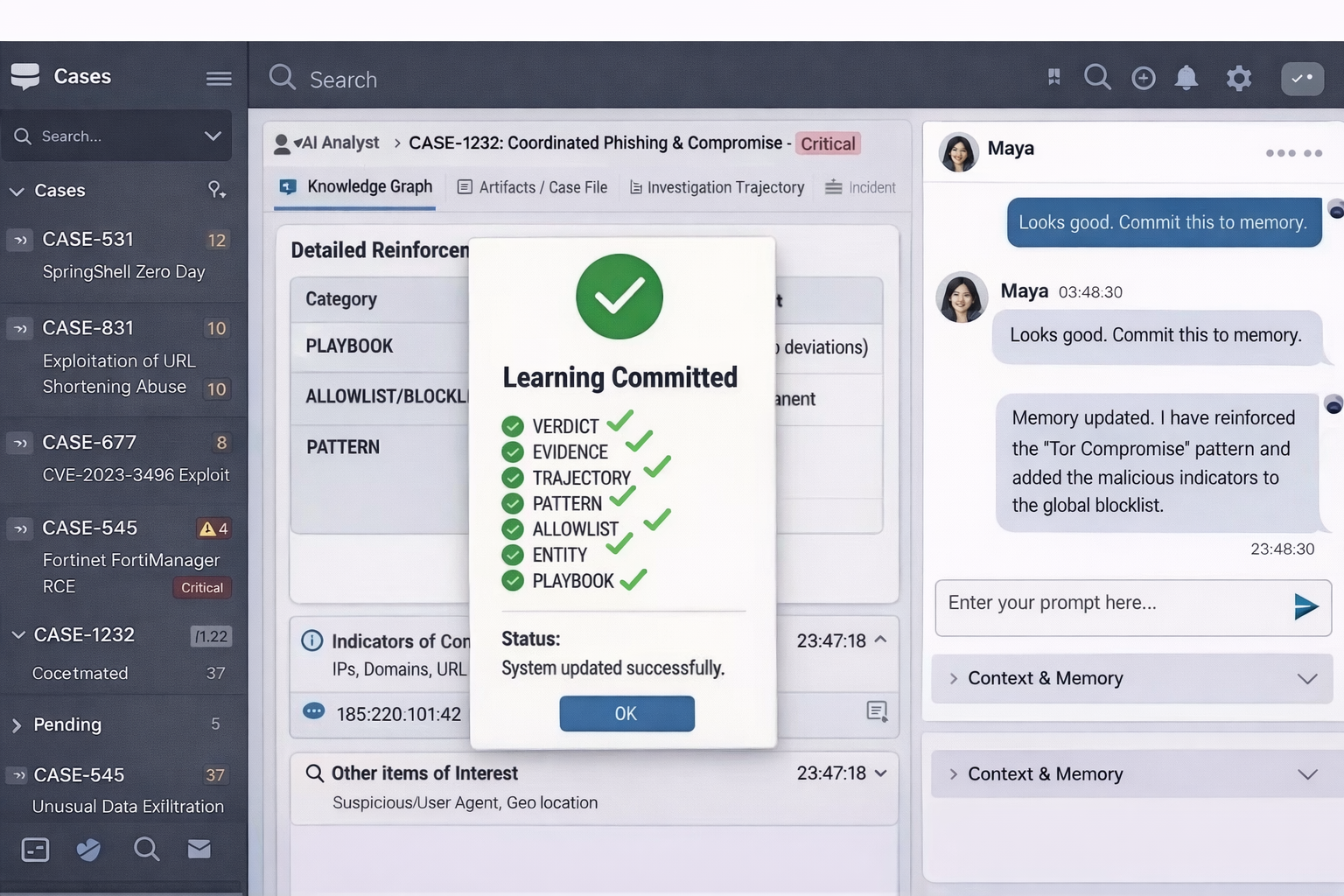
Instead of ending an investigation with a chat transcript, the system generates a structured artifact that captures what actually matters:
- The verdict, and the evidence that supported it
- The attack trajectory, step by step
- The entities involved, and how they relate
- The pattern, abstracted from surface indicators
- The assumptions that failed, and the controls that mattered
That package explains what happened while teaching the system how the attack works.
This is what Maya already did instinctively as a senior analyst. When she closed an incident, she carried forward a mental model of how that attack unfolded and what would stop it next time. Structured learning packages make that reasoning explicit, reusable, and shareable. They turn individual experience into institutional memory.
How Learning Compounds Over Time
With structured learning, the end of an investigation is the beginning of improvement.
When an analyst corrects an agent, the system doesn’t just log that the outcome was wrong. It replays the investigation to understand why. It extracts attacker steps, maps entity relationships, and identifies where assumptions broke. When an investigation is confirmed as correct, the same process happens. Success is analyzed as carefully as failure.
From there, the system generates a learning package and proposes concrete updates:
- refining investigation logic
- adjusting playbook steps,
- or modifying allowlists and blocklists that influenced the outcome
Nothing is committed blindly. Changes are reviewed by humans before they alter system behavior. Learning is auditable, reversible, and bounded.
Over time, the system stops starting from scratch, and investigations get shorter while decisions get more consistent. Entire classes of incidents begin to disappear because the conditions that enabled them have been removed. The system remembers the answer and the reasoning.
Why This Solves the Trust Problem
Distrust for A in cybersecurity stems from systems that can’t be explained, audited, or rolled back.
Most AI SOC tools ask teams to trust the model’s judgment, leaving them hoping the system is improving without being able to prove it. Structured learning flips that dynamic, as trust shifts from intuition to process. Every conclusion is tied to evidence, every improvement is traceable to a specific investigation, and nothing changes without review.
If an organization can tolerate junior analysts making inconsistent decisions at 2 a.m., then a system that applies the same reasoning every time, documents its steps, and improves deliberately rather than through tribal knowledge is already an upgrade.
Trust comes from knowing how the system thinks, what it changed, and why.
The Bigger Implication
Faster triage by itself may clear the queue, but it doesn’t reduce the risk. These AI SOC tools optimize response with chat memory, but structured learning enables adaptation. It’s what stops incidents from happening again.
Six months later, Maya’s team didn’t feel faster; they felt quieter, with fewer escalations and fewer repeats, because the SOC had finally learned what mattered instead of relearning the same failures.

The Emerging Patch Gap

Why Gartner’s AI Agent Reasoning Report Matters for Security Operations
